I am an Associate Professor (Universitair Hoofddocent) at the University of Amsterdam, where I co-direct the AMLab with Max Welling. I am also an Assistant Professor (on leave) at Northeastern University, where I continue to advise and collaborate.
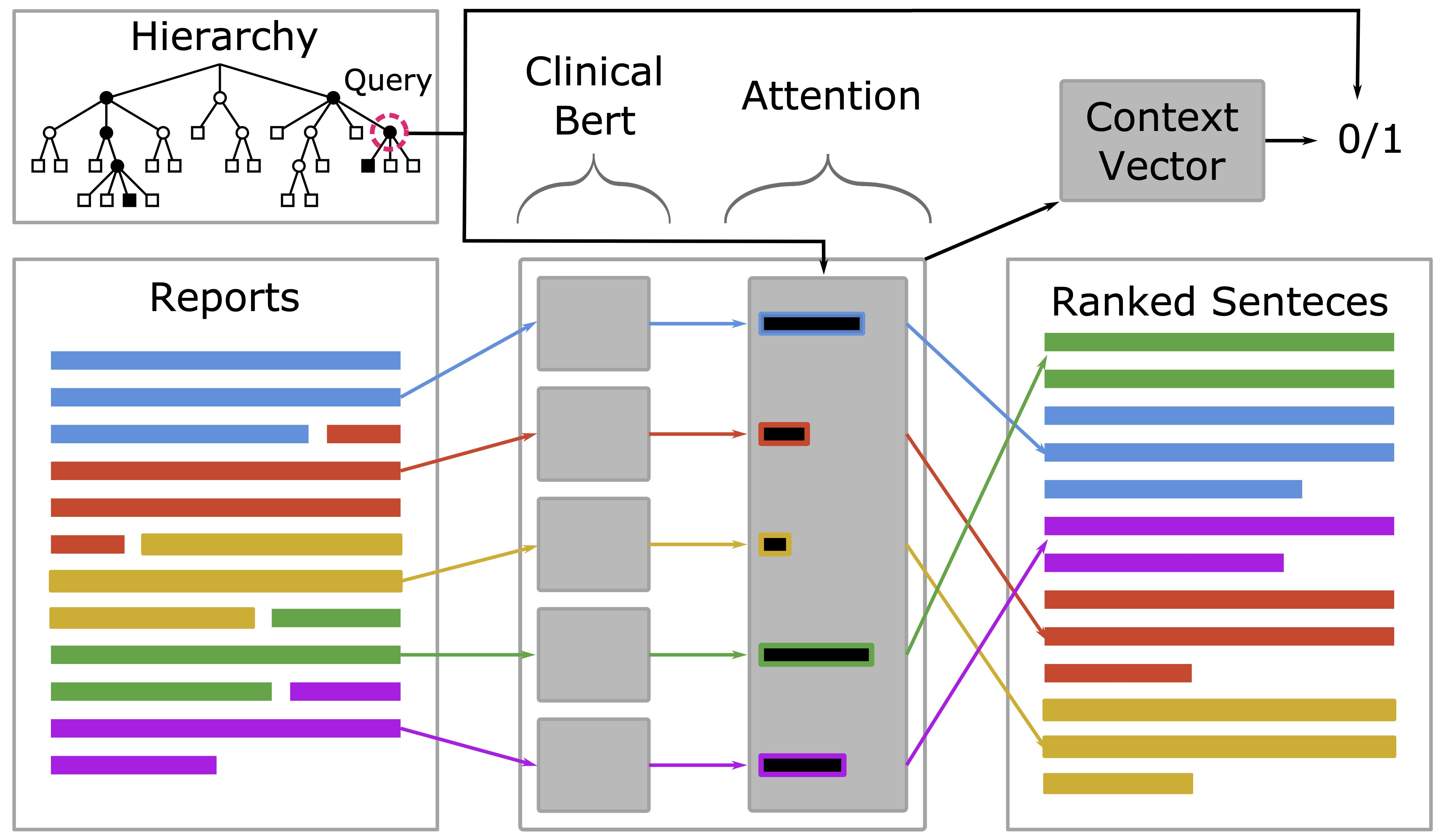
My research develops models for artificial intelligence by combining probabilistic programming and deep learning. Our work seeks to understand what inductive biases can enable models to generalize from limited data. These inductive biases can take the form of a simulator that incorporates knowledge of an underlying physical system, causal structure, or symmetries of the underlying domain. We combine model development with research on methods for inference in these models. We also put this work into practice in collaborations with researchers in robotics, NLP, healthcare, and the physical sciences.
The technical backbone in much of our work is probabilistic programming. I am one of the creators of Anglican, a probabilistic language based on Clojure. My group currently develops Probabilistic Torch, a library for deep generative models that extends PyTorch. I am writing a book on probabilistic programming, a draft of which is available on arXiv. I am also a co-chair of the international conference on probabilistic programming (PROBPROG).
News
SEP 2021 ∙ As of 1 September, I will start at the University of Amsterdam and will be on leave from Northeastern University. I will continue to advise current students, but am not recruiting PhD students or postdocs at Northeastern this cycle. I will participate in PhD recruiting through ELLIS, as will other faculty at AMLab. Please contact me at my UvA address with inquiries.
JUL 2021 ∙ I am delighted to have received the NSF CAREER award award for my research on deep learning and probabilistic programming!
JUL 2021 ∙ Robin Walters has received his first grant as PI for his work on representation-theoretic foundations of deep learning under the NSF the Scale MoDL program!
JUN 2021 ∙ The NSF has funded joint work on MDP abstractions with Lawson Wong, Rob Platt, and Robin Walters!
MAY 2021 ∙ Sam and Heiko’s paper on inference combinators will appear at UAI 2021!
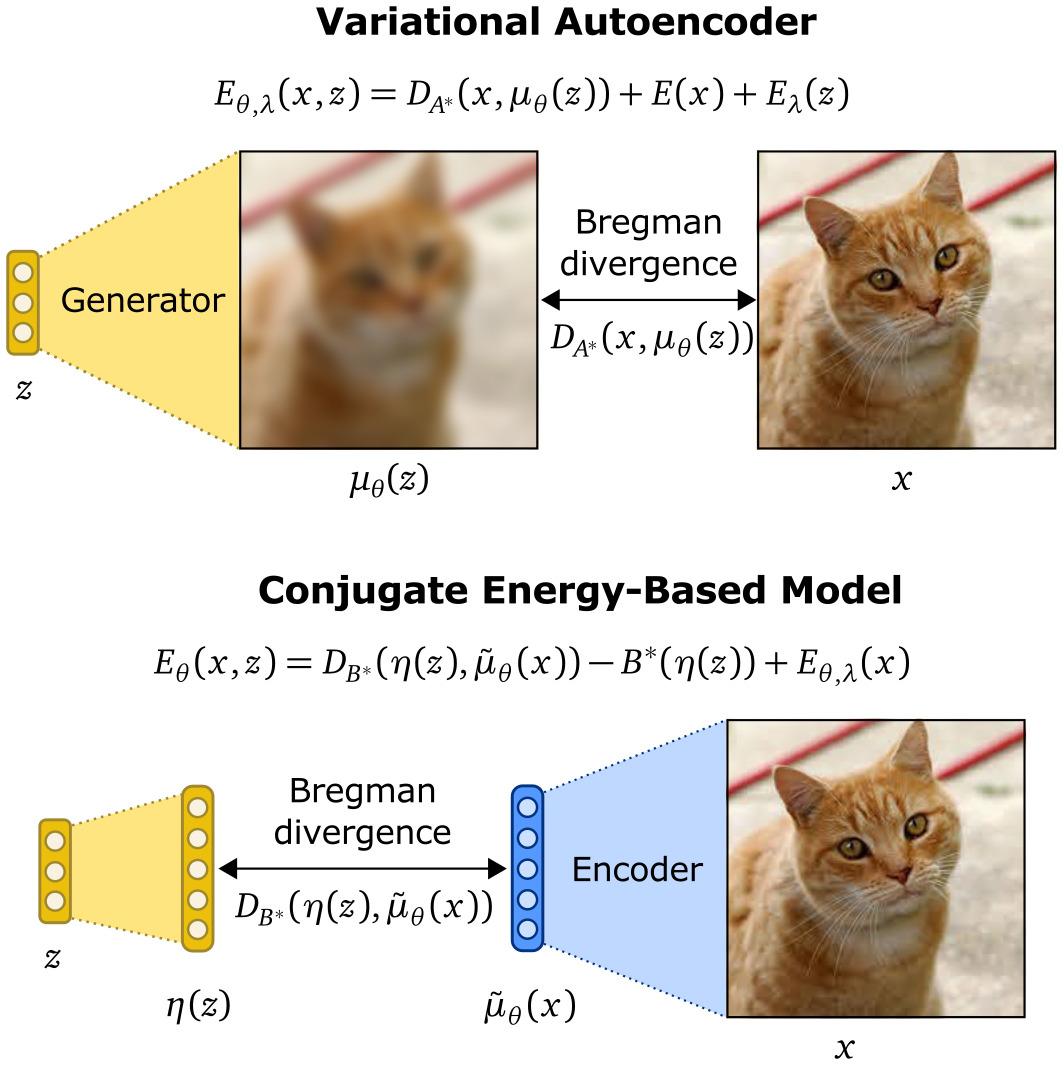
MAY 2021 ∙ Hao’s and Babak’s paper on Conjugate Energy-based Models was will appear at ICML 2021!
JAN 2021 ∙ Alican’s and Babak’s paper on rate-regularization and generalization in VAEs will appear at AISTATS 2021.
JAN 2021 ∙ Our group will be presenting 3 extended abstracts at AABI this year [1, 2, 3].
DEC 2020 ∙ Ondrej’s paper on action priors will appear at AAMAS 2021.





Current Students and Postdocs










Working Papers

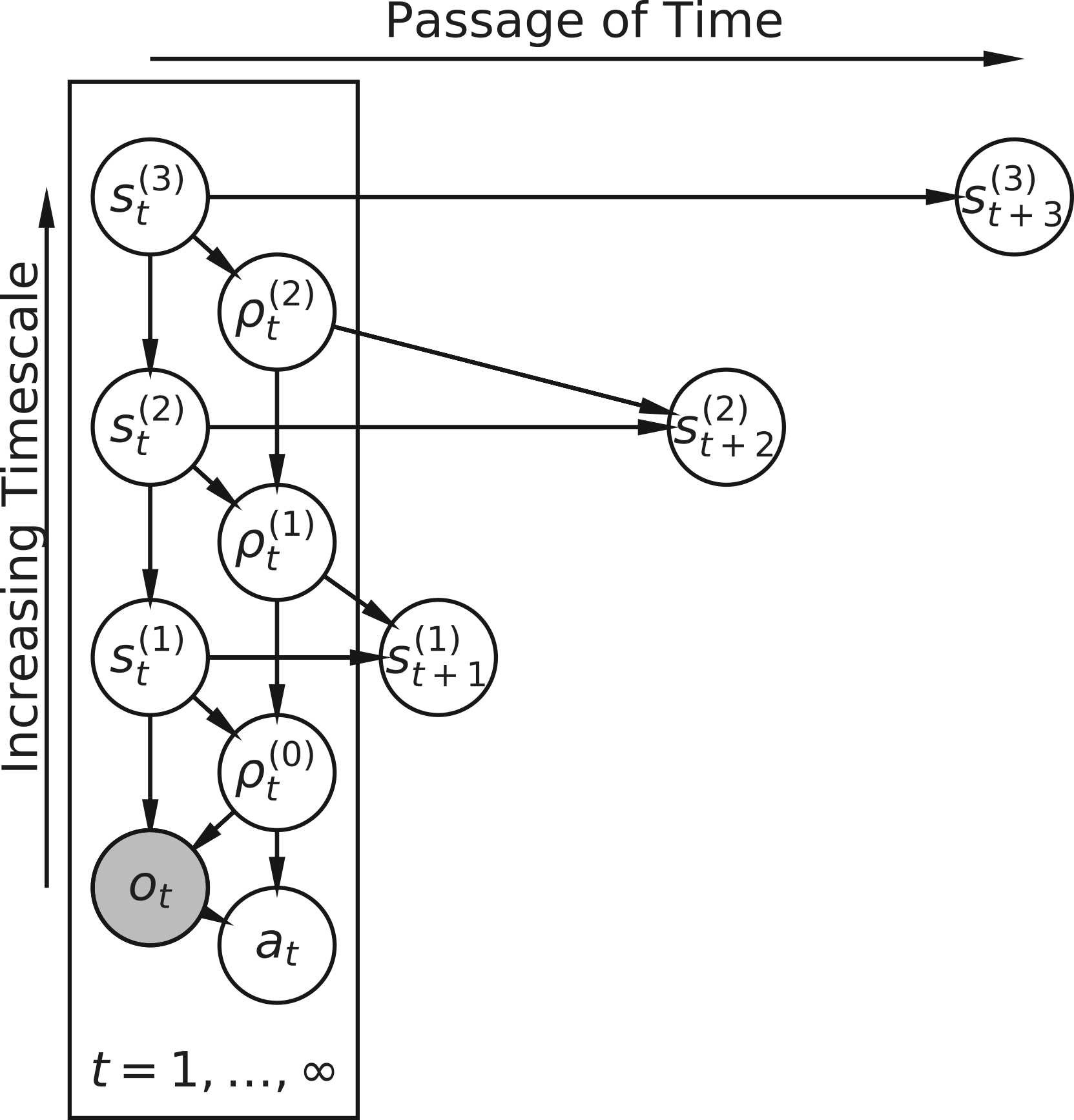
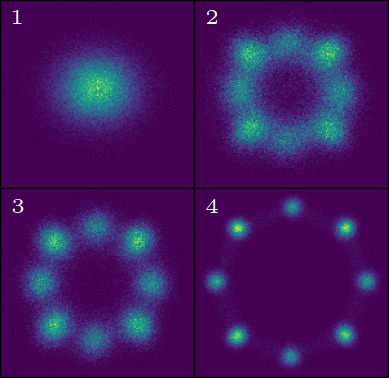
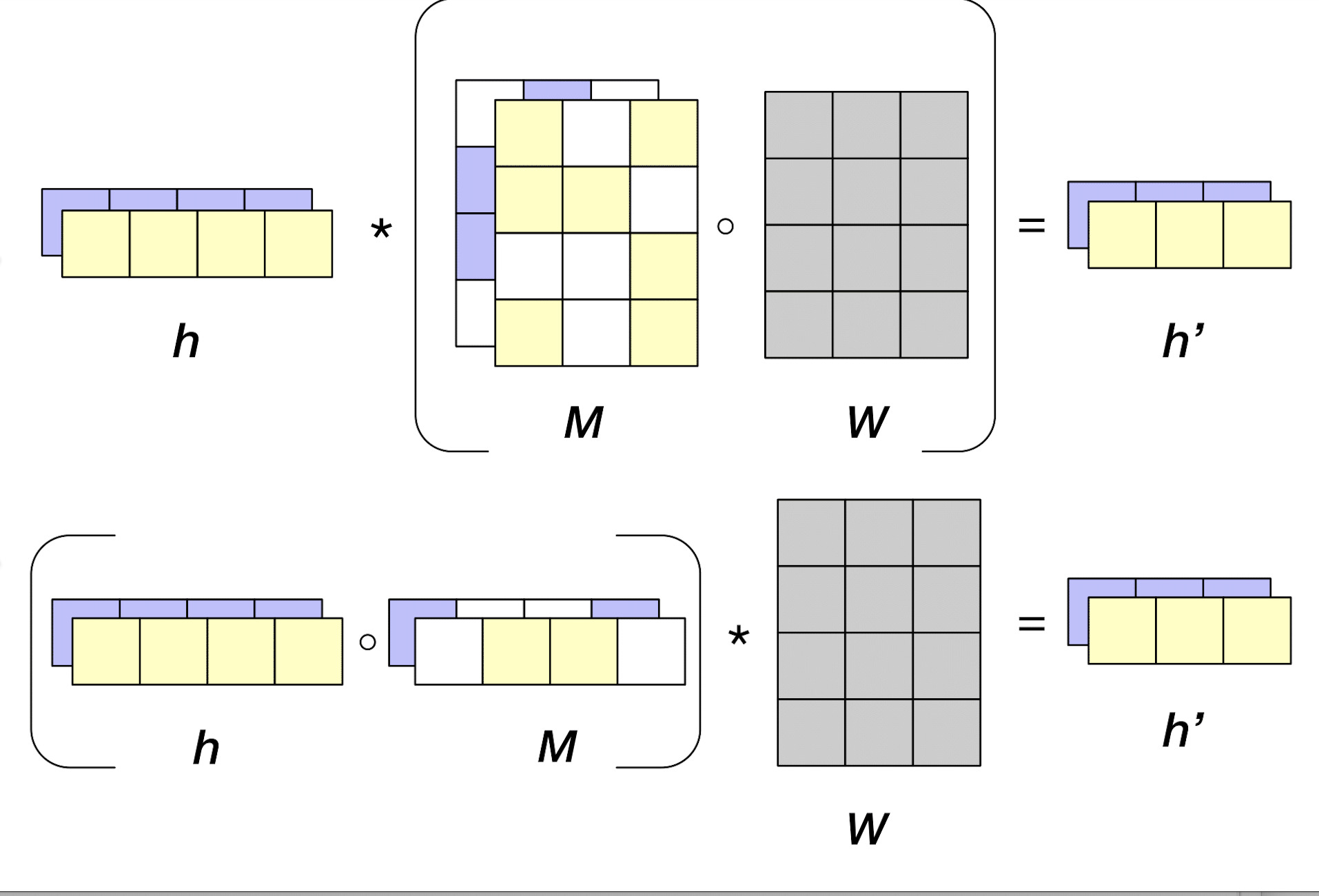
Selected Papers
3rd Symposium on Advances in Approximate Bayesian Inference (AABI 2021)